
“Attention is All You Need” là một trong những paper có tầm ảnh hưởng nhất trong những năm gần đây, đặc biệt là trong lĩnh vực dịch máy. Trước đây, RNN được xem như là khung xương của của kiến trúc dịch máy nói riêng và trong nhiều tác vụ trong NLP nói chung bởi lẽ cấu trúc thiết kế phù hợp của kiến trúc này (kiến trúc hồi quy – thích hợp trong nhiệm vụ xử lý chuỗi). Tuy nhiên với sự ra đời của bài báo này đã khiến cho mọi người hết sức kinh ngạc khi tác giả đã giới thiệu kiến trúc Transformer , một kiến trúc không sử dụng kiến trúc hồi quy mà chỉ sử dụng một kỹ thuật gọi là attention để giải quyết. Bài báo này được xem như là một làn gió mới trong lĩnh vực xử lý ngôn ngữ tự nhiên và ngày nay còn áp dụng trong các tác vụ xử lý ảnh.
1. Tại sao lại là transformer ?
- Thứ nhất, kiến trúc của RNN là một kiến trúc tuần tự khó có thể thực hiện việc tính toán song song, kết quả sau phải đợi kết quả trước để thực hiện nên không tận dụng được sức mạnh của GPU.
- Thứ hai, kiến trúc RNN khó có thể ghi nhớ được các phụ thuộc trong phạm vi dài (ngữ nghĩa của câu dài), dẫn đến mất mát thông tin.
- Transformer sẽ mô hình hoá tất cả các phụ thuộc bằng cơ chế tự chú ý (self-attention) , thay vì chỉ sử dụng một lần self-attention, Transformer sẽ sử dụng nhiều cơ chế self-attention gọi mà multi-head attention để tính toán trọng số liên quan của nhiều đầu ra cho một đầu vào duy nhất.
- Trong thực tế, những từ sẽ bị ảnh hưởng phụ thuộc vào vị trí của nó trong câu, tuy nhiên self-attention lại không xử lý được vấn đề đó. Để giải quyết vấn đề này, tác giả đã đề xuất mã hoá vị trí của từng từ theo vị trị của nó trong câu, sau đó sẽ được kết hợp với vector mã hoá của từ đó tương ứng trong câu.
2. Sơ lược một chút về dịch máy trong mạng Nơ-ron
Dịch máy cốt lõi của nó chỉ đơn giản là ánh xạ một câu này sang một câu khác. Các câu bao gồm nhiều từ, vì vậy việc này tương đương với việc ánh xạ một chuỗi ký tự này sang một chuỗi ký tự khác. Việc mapping một câu (sequence) sang một câu khác (sequence) là một nhiệm vụ phổ biến trong xử lý ngôn ngữ tự nhiên (NLP). Vì vậy người ta đã nghĩ ra nhiều phương pháp để thực hiện việc ánh xạ như thế, bài toán này được gọi chung là sequence to sequence (seq2seq).
Hầu hết các tác vụ trong seq2seq đều thực hiện theo mô hình Mã hoá – Giải mã (Encoder-Decoder), ý tưởng đơn giản của bộ mã hoá đó chính là biến đổi câu input đầu vào sang một biểu diễn trung gian, sau đó chuyển biểu diễn đó sang bộ giải mã để tạo ra chuỗi đầu ra. Các mô hình này được đào tạo làm sao để tối đa khả năng tạo ra chuỗi chính xác bằng cách phạt khi bộ giải mã cho kết quả sai và thưởng khi bộ giải mã cho kết quả đúng.

Ví dụ về mô hình seq2seq
Trước Transformer, thì kiến trúc RNN thành công nhất và được sử dụng cho cả bộ Mã hoá và Giải mã, với cơ chế tự đệ quy tuần tự hoàn toàn giống bản chất của ngôn ngữ (từ trái qua phải hoặc từ phải qua trái tuỳ theo ngôn ngữ, vùng miền) thì RNN dường như sinh ra là để thực hiện nhiệm vụ này. Vì thế, việc sử dụng RNNs cho nhiệm vụ này là điều vô cùng hợp lý. Thế nhưng, RNN chỉ phù hợp cho những câu ngắn, đối với những câu dài thì kiến trúc này lại gặp một vấn đề. Theo như hình trên, biểu diễn trung gian (S-context) đang có bị nút thắc cổ chai về thông tin, tất cả ngữ cảnh của câu chỉ được biểu diễn bằng duy nhất một vector context S, chính đều này đã gây ra mất mát thông tin khi câu đầu vào dài. Một vấn đề tiếp theo đó chính là bộ giải mã cần thông tin khác nhau ở những thời điểm khác nhau, điều này cũng có thể dễ hiểu thôi, vì ở ngôn ngữ nguồn và ngôn ngữ đích không phải lúc nào cũng tương ứng về nghĩa ở các từ. Ví dụ:
- Nguồn: She is a beautiful girl
- Đích: Cô ấy là một cô gái đẹp
Rõ ràng từ đầu vào của câu nguồn là “beautiful’ tương ứng với từ của câu đích là “đẹp”, tạo ra sự phụ thuộc lâu dài mà RNN phải thực hiện tất cả trong khi đọc câu nguồn và tạo câu đích. Mặc khác, khi đã giải mã ra được từ “cô gái” thì nó cần biết được “cô gái ấy” như thế nào mà không cần phải nhớ về “cô gái” nữa, vấn đề này chính là động lực đằng sau của cơ chế tự chú ý (attention).
Về mặt trực giác, chúng ta thấy rằng cơ chế “attention” sẽ giúp bộ giải mã nhìn lại toàn bộ câu và trích xuất thông tin cần thiết trong quá trình giải mã. Cụ thể cơ chế đã cho phép bộ giải mã truy cập vào tất cả các trạng thái ẩn của bộ mã hoá. Tuy nhiên bộ giải mã cần phải đưa ra dự đoán duy nhất cho từ tiếp theo, vì vậy chúng ta không thể chỉ chuyển nó qua một chuỗi đại diện cuối cùng mà cần phải thông qua các vector tóm tắt (các vector biểu diễn các từ ở encoder). Vì thế attention đã thực hiện tính toán trọng số ở các trạng thái ẩn để quyết định nhận và bỏ qua các trạng thái ẩn mà nó cho rằng có ảnh hưởng. Sau đó, bộ giải mã được thông qua một tổng trọng số của các trạng thái ẩn để sử dụng để dự đoán từ tiếp theo. Trọng số này có thể tính toán bằng nhiều cách, bên dưới attention-weight được tính bằng dot product.

Cơ chế attention
3. Tại sao RNN là chưa đủ ?
Với những gì ta vừa tìm hiểu ở trên, dường như rằng việc áp dụng cơ chế attention sẽ giúp giải quyết được vấn đề với kiến trúc Encoder-Decoder sử dụng mô hình RNN. Tuy nhiên, sẽ có những thiếu sót trong mô hình này mà Transformer đang cố gắng giải quyết.
Thứ nhất, đó là tính chất tuần tự của RNN. Khi chúng ta xử lý chuỗi bằng cách sử dụng RNN thì mỗi trạng thái ẩn đằng sau sẽ phụ thuộc vào trạng thái ẩn trước đó. Điều này chính là trợ ngại lớn nhất khi áp dụng train mô hình trên GPU vì GPU có khả năng thực hiện song song hoá, không cần phải đợi kết quả trước đó.
Thứ hai, RNN khó khăn trong việc ghi nhớ các phụ thuộc tầm xa trong mạng. Để khắc phục nhược điểm đó, LSTM ra đời (link tại đây) nhưng chúng cũng gặp phải vấn đề đó là chi phí tính toán quá lớn, trong khi đó vẫn không thể giải quyết được vấn đề tuần tự. Về nguyên tắc thì chúng có thể nhớ được câu trúc câu dài nhưng không thể xử lý câu quá dài. Ngoài ra, một số từ ngữ chỉ thực sự trở nên rõ ràng trong một hoàn cảnh cụ thể đồng thời nó không chỉ thể hiện được mối quan hệ giữa những từ trước nó mà còn cả sau nó, ví dụ như từ “than” trong câu “She is taller than me” và trong câu “I have no choice other than to write this blog post” được sử dụng với hai nghĩa hoàn toàn khác nhau. Trong khi đó, các mã đầu ra (output token) cũng phụ thuộc vào nhau, ví dụ như trong câu “Neither he nor I knew about deep learning” thì token “nor” sẽ phụ thuộc vào mệnh đề phủ định “Neither”. Chính vì những điều trên mà RNN không thể xử lý được.

Sự phụ thuộc mà RNN phải xử lý. Độ dài đường dẫn tỷ lệ với độ dài của đầu vào + đầu ra.
Về bản chất thì có 3 loại phụ thuộc trong dịch máy mạng thần kinh nơ-ron, đó là sự phụ thuộc giữa :
- Giữa input và output token
- Giữa các token trong input
- Giữa các token trong output
Cơ chế attention đã giải quyết được vấn đề phụ thuộc thứ nhất bằng cách tính toán trọng số attention-weight giữa S context trong bộ giải mã ở mỗi timestep với tất cả hidden context ở Encoder. Ý tưởng mới của Transformer là mở rộng cơ chế này cho cả các câu xử lý đầu vào và đầu ra. Thay vì đi từ trái sang phải bằng cách sử dụng RNN, tại sao chúng ta không cho phép bộ mã hóa và bộ giải mã xem toàn bộ chuỗi đầu vào cùng một lúc , trực tiếp mô hình hóa những phụ thuộc này bằng cách sử dụng cơ chế tự chú ý (self-attention) ?

Sự phụ thuộc mà Transformer phải học. Bây giờ độ dài đường dẫn độc lập với độ dài của câu nguồn và đích.
Đây là ý tưởng cơ bản đằng sau Transformer. Bây giờ, chúng ta chuyển sang các chi tiết của việc thực hiện. Thành phần quan trọng của Transformer là khối Đa đầu chú ý (Multi-Head attention). Chúng ta hãy xem xét thành phần này một cách chi tiết.
4. Multi – Head attention: Thành phần chính của Transformer
Cơ chế self-attention trong Transformer được xem như là một cách tính toán mức độ liên quan của một bộ giá trị (Values) dựa trên một số khoá (Keys) và truy vấn (Queries). Về cơ bản, cơ chế self-attention được sử dụng như một cách để mô hình tập trung vào thông tin có liên quan dựa trên những gì mà nó đang xử lý. Theo truyền thống, attention-weight là mức độ liên quan của trạng thái ẩn bộ mã hóa values) trong việc xử lý trạng thái bộ giải mã (queries) và được tính toán dựa trên trạng thái ẩn bộ mã hóa (keys) và trạng thái ẩn bộ giải mã (queries).

Trong ví dụ này, query là từ được giải mã (“犬” có nghĩa là con chó) và cả keys và values đều là câu nguồn. Attention-weight thể hiện mức độ liên quan và trong trường hợp này là lớn đối với từ “dog” và nhỏ đối với những từ khác.
Trong cách nghĩ này, chúng ta thấy rằng các keys, values và queries đều có thể là bất kỳ thứ gì. Thậm chí, những thành phần này có thể giống nhau. Ví dụ cả keys và values đều có thể là input embedding. Phần mã hoá, chúng sử dụng embedding của câu nguồn để làm values, keys và queries; trong khi đó, phần giải mã sẽ sử dụng output của Encoder để làm values và key và embeding của câu đích (các từ đã được dự đoán) làm queries.
Nếu chúng ta chỉ tính toán một self-attention weight thì sẽ rất khó để nắm bắt các khía cạnh khác nhau của đầu vào bởi vì nó có xu hướng tập trung vào chính bản thân của nó. Nhưng trong thực tế, ta cần là tính toán mức độ liên quan giữa những từ khác nhau trong câu, giải pháp được đề xuất là thay vì sử dụng nhiều self-attention cùng một lúc để học được nhiều attention weight khác nhau giúp chú ý đến nhiều chỗ khác nhau trong cùng một câu. Vì bản thân mỗi self-attention sẽ cho ra một ma trận weight attention riêng nên ta sẽ tiến hành concat các ma trận này và nhân với ma trận trọng số WO để ra một ma trận attention duy nhất (weighted sum).

Cách tính weighted sum
Dưới đây chính là ý tưởng của khối Multi-Head attention kèm theo mã Pytorch

Multi-head Attention
##################################################################
"""
Class HeadAttention: thực hiện tìm giá trị 3 vector K, Q, V sau đó tính attention
Đối số đầu vào:
- d_model: chiều dài của vector embedding
- d_feature: chiều dài của vector K,Q,V sau khi nhân matrix input với từng W_k, W_q và W_v tương ứng
"""
class HeadAttention(nn.Module):
def __init__(self, d_model=512, d_feature=64, drop=.1):
super().__init__()
# Khởi tạo 3 ma trận trọng số W_k, W_q, W_q
self.W_k = nn.Linear(d_model, d_feature)
self.W_q = nn.Linear(d_model, d_feature)
self.W_v = nn.Linear(d_model, d_feature)
self.attention = ScaleDotProduct(drop)
def forward(self, queries, keys, values, mask=None):
Q = self.W_q(queries)
K = self.W_k(keys)
V = self.W_v(values)
return self.attention(Q,K,V,mask)
##################################################################
"""
Class MultiHeadAttention: Thực hiện tính attention trên nhiều head
Đối số đầu vào:
+ n_heads: Số lượng head
+ d_model: Kích thước vector embedding
+ d_feature: Kích thước vector K
"""
class MultiHeadAttention(nn.Module):
def __init__(self, n_heads=8, d_model=512, d_feature= 64, drop=.1):
super().__init__()
self.n_heads = n_heads
self.attentions = nn.ModuleList(HeadAttention(d_model=d_model,d_feature=d_feature,drop = drop) for _ in range(n_heads))
# Tạo một ma trận W_0 để trả về kích thước ban đầu
self.W_0 = nn.Linear(n_heads*d_feature, d_model)
def forward(self, queries, keys, values, mask=None):
x = [attention(queries, keys, values, mask) for _, attention in enumerate(self.attentions)]
x = torch.cat(x, dim=-1)
return self.W_0(x)
Như đã thấy, cấu trúc của việc tính toán seft-attention rất đơn giản: nó áp dụng một phép chuyển đổi tuyến tính duy nhất cho các truy vấn đầu vào, khóa và giá trị, tính toán điểm số chú ý giữa mỗi truy vấn và khóa, sau đó sử dụng nó để cân các giá trị và tổng chúng lên. Khối Multi-head Attention chú ý chỉ áp dụng nhiều khối song song, nối các đầu ra của chúng, sau đó áp dụng một phép biến đổi tuyến tính duy nhất.
Scaled Dot Product Attention
Giống như cơ chế “attention”, Transformer sử dụng một cơ chế gọi là Scaled dot Product Attention nhằm tính attention weight như sau:
![]()
Scale Dot Product Attention
Trong đó: Q, K, V là các ma trận tương ứng là queries, keys và values. Việc tiến hành chia cho chiều kích thước ủa ma trận Q/K/V nhằm mục đích tránh tránh tràn luồng nếu số mũ là quá lớn.
##################################################################
'''
Class ScaleDotProduct: Tính giá trị attention của 3 vector K,Q,V
Đối số đầu vào:
+ drop: Giá trị bỏ học, mặc định .1
'''
class ScaleDotProduct(nn.Module):
def __init__(self, drop=.1):
super().__init__()
self.drop = nn.Dropout(drop)
def forward(self, Q, K, V, mask=None):
d_k = K.size(-1) # Chiều dài của vector key, chiều dài này khác chiều dài d_model
attention_scores = torch.matmul(K,Q.transpose(-2,-1))/math.sqrt(d_k)
attention_scores = F.softmax(attention_scores,-1)
if mask != None:
mask = mask.unsqueeze(1)
attention_scores = attention_scores.masked_fill(mask == 0,0)
attention_scores = self.drop(attention_scores)
return torch.matmul(attention_scores,V)
5. Transformer – kiến trúc hoàn chỉnh
Kiến trúc tổng thể của Transformer như sau

Kiến trúc của transformer
Như bạn có thể thấy, Transformer vẫn sử dụng thiết kế bộ mã hóa-giải mã cơ bản của các hệ thống dịch máy thần kinh truyền thống. Phía bên trái là bộ mã hóa và phía bên phải là bộ giải mã. Đầu vào của Encoder là kết hợp của embedding của input và vị trí của từ trong câu, trong khi đó đầu vào của Decoder là embedding của các từ được của các đầu ra (từ được dự đoán ở Decoder) ở thời điểm đó. Bộ mã hoá và giải mã bao gồm N khối giống nhau xếp chồng lên nhau.
a. Bộ mã hoá – Encoder

Encoder
Mỗi khối trong bộ mã hoá lại bao gồm 2 khối nhỏ hơn (sub-layer). Khối đầu tiên là Multi-head Attention như đã đề cập ở trên. Còn lại chỉ là các mạng chuyển tiếp đơn giản. Giữa mỗi lớp con sẽ có một kết nối residual connection và theo sau đó chính là một lớp chuẩn hoá. Việc sử dụng residual connection nhằm giúp mạng giữ được thông tin trước đó và việc chuẩn hoá sau đó nhằm mục đích giúp cho có được sự đồng bộ trong phân phối trong dự liệu do việc mô hình càng sâu sẽ có nhiều layer cùng với đó là có nhiều hàm kích hoạt, nó sẽ làm biến đổi đi phân phối của dữ liệu. Phương trình đầu ra của mỗi khối sẽ có dạng như sau:

Dưới đây là mã pytorch cho một block trong phần encoder:
##################################################################
"""
Class Encoder: Mã hoá một câu đầu vào biểu diễn thành các vector ngữ nghĩa
Đối số đầu vào:
+ d_model: Kích thước vector nhúng từ
+ d_feature: Kích thước của vector K
+ dff: Số lượng node trong feedforward
+ n_heads: số lượng head
"""
class Encoder(nn.Module):
def __init__(self, d_model=512, d_feature=64, d_ff=2048, n_heads=8, drop=.1):
super().__init__()
self.MultiHeadAttention = MultiHeadAttention(n_heads=n_heads, d_model=d_model, d_feature=d_feature,
drop=drop)
self.norm1_layer = nn.LayerNorm(d_model)
self.norm2_layer = nn.LayerNorm(d_model)
self.drop = nn.Dropout(drop)
self.feed_forward = nn.Sequential(
nn.Linear(d_model, d_ff),
nn.LeakyReLU(.1),
nn.Linear(d_ff, d_model)
)
def forward(self,x, mask=None):
features = self.MultiHeadAttention(x, x, x, mask=mask)
#norm
norm1 = self.norm1_layer(features)
# skip connection
x = x + self.drop(norm1)
#feed forward
ff = self.feed_forward(x)
# norm
norm2 = self.norm2_layer(ff)
# skip connection
return x + self.drop(norm2)Toàn bộ Encoder sẽ như sau
##################################################################
"""
Class Encoders: Mã hoá một câu đầu vào biểu diễn thành các vector ngữ nghĩa
Đối số đầu vào:
+ d_model: Kích thước vector nhúng từ
+ d_feature: Kích thước của vector K
+ dff: Số lượng node trong feedforward
+ n_heads: số lượng head
+ n_layers: Số lượng Encoder
"""
class Encoders(nn.Module):
def __init__(self, d_model=512, d_feature=64, d_ff=2048,
n_heads=8, n_layers=10, drop=.1,max_length=500):
super().__init__()
self.encoders = nn.ModuleList([Encoder(d_model, d_feature, d_ff,n_heads, drop) for _ in range(n_layers)])
self.position_encoding = PositionEncoding(d_model,max_length)
def forward(self, x: torch.FloatTensor, mask = None):
# Mã hoá vị trí trong câu
x = self.position_encoding(x).float()
# Mã hoá
for encoder in self.encoders:
x = encoder(x, mask)
return x
Thoạt nhìn, Transformer có vẻ đáng sợ nhưng nếu ta tách ra từng phần nhỏ thì sẽ không phức tạp đến như vậy.
b. Bộ giải mã – Decoder

Decoder
Bộ giải mã về cơ bản là rất giống với bộ mã hoá nhưng có một chút khác biệt đó là khối Multi-head Attention được thay thế bởi Mask Multi-head Attention. Nguyên nhân cho việc này là vì một từ ở vị trí hiện tại sẽ phụ thuộc vào những từ đã được giải mã trước đó. Việc che giấu đi những từ phía sau nhằm mục đích tránh hiện tượng “nhìn trước” kết quả. Nếu chúng ta không che đi kết quả phía sau thì mô hình có thể lặp lại toàn bộ câu đích (nói cách khác là mô hình không học được điều gì cả).
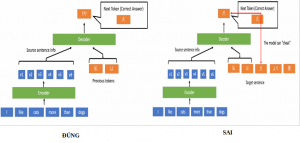
Hình ảnh minh hoạ
Dưới đây là mã pytorch cho Decoder-block
##################################################################
"""
Class Decoder: Giải mã
Đối số đầu vào:
+ d_model: Kích thước vector nhúng từ
+ d_feature: Kích thước của vector K
+ dff: Số lượng node trong feedforward
+ n_heads: số lượng head
"""
class Decoder(nn.Module):
def __init__(self, d_model=512, d_feature=64, d_ff=2048, n_heads=8, drop=.1):
super().__init__()
self.MultiHeadAttention = MultiHeadAttention(n_heads=n_heads, d_feature=d_feature,
d_model=d_model, drop=drop)
self.drop = nn.Dropout(drop)
self.norm1_layer = nn.LayerNorm(d_model)
self.norm2_layer = nn.LayerNorm(d_model)
self.norm3_layer = nn.LayerNorm(d_model)
self.feed_forward = nn.Sequential(
nn.Linear(d_model,d_ff),
nn.LeakyReLU(.1),
nn.Linear(d_ff,d_model)
)
def forward(self, encoder_output, x, encoder_mask=None , decoder_mask=None):
# Tính attention mask
mask_attentions = self.MultiHeadAttention(x, x, x, mask = decoder_mask)
# norm kq vừa tính
norm1 = self.norm1_layer(mask_attentions)
# skip connection
x = x + self.drop(norm1)
# Tính attention lần 2
#key, value lấy từ encoder_output
attentions = self.MultiHeadAttention(x, encoder_output, encoder_output, mask=encoder_mask)
# norm
norm2 = self.norm2_layer(attentions)
# skip connection
x = x + self.drop(norm2)
# ff
x = self.feed_forward(x)
# norm
norm3 = self.norm3_layer(x)
# skip connection
return x + self.drop(norm3)Còn đây là Transformer Decoder block
##################################################################
"""
Class Decoders: Giải mã
Đối số đầu vào:
+ d_model: Kích thước vector nhúng từ
+ d_feature: Kích thước của vector K
+ dff: Số lượng node trong feedforward
+ n_heads: số lượng head
+ n_layers: số lượng decoder
"""
class Decoders(nn.Module):
def __init__(self, d_model=512, d_feature=64, d_ff=2048, n_heads=8,
n_layers=10, drop=.1, max_length=500):
super().__init__()
self.decoders = nn.ModuleList([Decoder(d_model, d_feature, d_ff, n_heads, drop) for _ in range(n_layers)])
self.position_encoding = PositionEncoding(d_model, max_length)
def forward(self, output_encoder, x, encoder_mask = None, decoder_mask = None):
x = self.position_encoding(x)
for decoder in self.decoders:
x = decoder(output_encoder, x, encoder_mask , decoder_mask)
return x
c. Mã hoá vị trí – Positional Encodings
Không giống như RNN hoặc các mạng hồi quy khác, Transformer không thể nắm bắt được vị trí của các từ trong câu để xử lý nhưng trong thực tế thì điều đó là vô cùng cần thiết (ví dụ “Tôi cao hơn bạn” và “bạn cao hơn tôi” là hai câu khác nhau, nếu không nhận biết được vị trí thì có thể 2 câu này sẽ cho ra cùng một kết quả). Chính vì thế Positional Encodings ra đời nhằm khắc phục điều này. Dưới đây là công thức tính vị trí của một token mà tác giả đã đề xuất:
 Công thức tính vị trí của một token
Công thức tính vị trí của một token
Trong đó, pos chính là vị trí của của từ trong câu, PE là giá trị phần tử thứ i trong embeddings có độ dài d_model
class PositionalEmbedding(nn.Module):
def __init__(self, d_model, max_len=512):
super().__init__()
# Compute the positional encodings once in log space.
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len).unsqueeze(1).float()
div_term = torch.exp(torch.arange(0, d_model, 2).float() *
-(math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0)
self.weight = nn.Parameter(pe, requires_grad=False)
def forward(self, x):
return self.weight[:, :x.size(1), :] # (1, Seq, Feature)
Cuối cùng là Transformer hoàn chỉnh:
##################################################################
"""
Class Transformer: Kết hợp Encoders và Decoders
"""
class Transformer(nn.Module):
def __init__(self, voc_size, d_model=512, d_feature=64, d_ff = 2048,
n_heads = 8, n_layers=10, max_length=500, drop=.1):
super().__init__()
self.encoders = Encoders(d_model=d_model, d_feature = d_feature, d_ff = d_ff,
n_heads=n_heads, n_layers = n_layers, max_length=max_length, drop = drop)
self.decoders = Decoders(d_model=d_model, d_feature = d_feature, d_ff = d_ff,
n_heads=n_heads, n_layers = n_layers, max_length=max_length, drop = drop)
self.embbeding = Embedding(voc_size, d_model)
self.fc = nn.Linear(d_model, voc_size)
def forward(self,input_encoder, input_decoder, encoder_mask = None, decoder_mask=None):
encode_embedding = self.embbeding(input_encoder)
decode_embedding = self.embbeding(input_decoder)
output_encoders = self.encoders(encode_embedding,mask = encoder_mask)
output_decoders = self.decoders(output_encoders,decode_embedding,encoder_mask,decoder_mask)
return self.fc(output_decoders)
6. Tổng kết
Trên đây là toàn bộ bài giải thích về paper “Attention is All You Need” cũng như cách hoạt động của Transformer và mã pytorch kèm theo mà mình đã chọn lọc, tham khảo từ nhiều nguồn. Mong mọi người đọc và góp ý để bài viết sau sẽ chất lượng hơn. Mọi thắc mắc các bạn hãy để xuống dưới phần bình luận, mình sẽ giải đáp tốt nhất nếu có thể. Cảm ơn mọi người đã theo dõi bài viết.
7. Tài liệu tham khảo
https://mlexplained.com/2017/12/29/attention-is-all-you-need-explained/
https://arxiv.org/abs/1706.03762
https://viblo.asia/p/transformers-nguoi-may-bien-hinh-bien-doi-the-gioi-nlp-924lJPOXKPM
https://drive.google.com/drive/u/0/folders/1Wa6Qfz0wUSBKjc7HWBV2DinCuUBuh-WY
https://drive.google.com/drive/u/0/folders/1Wa6Qfz0wUSBKjc7HWBV2DinCuUBuh-WY




8 bình luận
There’s certainly a great deal to know about this subject. I like all of the points you made. Claudette Alisander Senzer
Thank you. Hope you will visit more often.
Simply wanna tell that this is very beneficial , Thanks for taking your time to write this. Eveline Ramsay Cleland
Hello! I could have sworn I’ve been to this blog before but after browsing through some of the post I realized it’s new to me. Anyways, I’m definitely happy I found it and I’ll be book-marking and checking back frequently!
I value the blog post. Fantastic. Paul Munnis
Awesome article post.Much thanks again.
Nhờ anh xem lại các hình minh họa bị lỗi, không hiển thị được ạ. Rất cảm ơn bài viết của anh
Cảm ơn bạn đã góp ý. Admin sẽ kiểm tra lại các hình ảnh bị lỗi.